Logbuch: developement log (german)¶
14. Oktober 2013¶
Das erste Problem wurde gesichtet: Genre Normalisierung. (Ich nenn es Sören.) Lösungsansatz mit einem Genre-Baum der von einer Genre-Liste von echonest abgeleitet wurde. Funktioniert eigentlich ganz anständig. Was fehlt wäre noch ein backtracking algorithmus der für folgendes genre alle möglichen resultate liefert:
>>> match('Pure Depressive Black Funeral Doom Metal') # yap, wirklich.
[('doom', 'funeral'), ('metal', 'black', 'pure'), ('metal', 'black', 'depressive')]
# Anmerkung: Geschafft! unter build_genre_path_all() verfügbar.
Die Resultate sind natürlich so gut wie Datenbank und wie der Input.
Der Input ist besonders schwierig da sich weder Fans noch Labels noch die einzelnen Mitglieder einer Band unter Umständen auch nur auf das genre eines einzelnen Albums einigen können.
Anektode dazu: Varg Vikernes, damals Gitarrist der Band Mayhem, ermordete den damaligen Frontmann unter anderen wegen Meinungsverschiedenheit ob die Band denn nun reinen ‘Black Metal’ oder doch eher ‘Depressive Black Metal’ spiele.
http://ikeaordeath.com/ ist eine passende Hommage für das Thema. Man beachte die teilweise angegebenen Genre Namen!
15. Oktober 2013¶
Die tolle iisys Hardware macht mal wieder Probleme. Heureka. Kein Internet.
Es gibt eine ganze Forschungsrichtung für das was ich mach: MIR - Music Information Retrieval. Gibt sogar teils schon Frameworks dazu wie MARYSAS. Auf deren Seite gibts auch eine Datensets (nicht frei aber) mit getaggten Genres. Allerdings als .wav files:
16. Oktober 2013¶
Hardware geht wieder... waren zu blöd zu merken dass es da noch ne externe NIC gab. Die geht dann auch problemlos. Schade dass wir dafür nicht bezahlt wurden wie unsere Kollegen. Hatte die Idee für Distanzen noch allgemein “Regeln” einzuführen. Beispielsweise eine Distanzfunktion kann einen Wert berechnen, aber dieser kann von einer Regel überschrieben werden.
Zurück zu unserem Genre Beispiel:
Die beiden Pfade (190, 0) und (175, 1) sollen ‘folk metal’ und ‘folk rock’ sein. Beide haben aber wie man sieht komplett unterschiedliche Pfade und bekämen daher eine Distanz von 1.0 zugewisen - obwohl beide genres jetzt nicht sehr weit entfernt sind. Daher könnten Regeln eingeführt werden die für bestimmte Pfade, oder allgemein Werte eine bestimmte Distanz festlegt. Diese Regeln könnten dann beispielsweise dynamisch durch Apriori oder auch manuell durch den User eingepflegt werden.
Ein Problem dass gelöst werden will:
Was passiert wenn man zu einem bestimmten Song nur Songs suchen will die in bestimmten Attributen ähnlich sind, beispielsweise ähnliches genre?
Einfach weiter im Graph traversieren und nur Attribute mit dieser lokalen Attributmaske betrachten?
17. Oktober 2013¶
Problem: (Ich nenns mal Sam): https://gist.github.com/sahib/7013716
Lösung war jetzt am Ende einfach: Man nehme die Single Linkage beider Cluster. Mit anderen Worten: Die kleinste Distanz die beim Vergleichen aller Elemente mit allen Elementen der anderen Liste entsteht. Ist einfach zu erklären und gibt im Grunde die ordentlichsten und realitätsnahesten Ergebnisse beim Vergleichen von Genres.
class Distance: Diese Klasse könnte bereits Regeln einführen und allgemein implementieren.
Eine REgel wäre zB: ‘rock’ ==> ‘metal’:0.0 (wieder bei unseren genre beispiel, soll aber allgemein sein). Die Regel heißt: Wer rock hört, hört mit einer hohen Wahrscheinlichkeit auch metal. Die 0.0 ist die Distanz die dafür angenommen wird (maximale ähnlichkeit.). Regeln können auch bidirektional sein:
‘rock’ <=> ‘metal’:0.0
in diesem Fall gilt auch das Inverse: Wer gern Metal hört, hört auch gern Rock.
23. Oktober 2013¶
Das Grobe Design steht im Grunde. Es wurde ein sphinx-dummy erstellt der auf RTD auch buildet. Unittest wurden für die meisten Module bereits implementiert, und bei jedem commit laufen die für python3 und python2 durch. Praktisch :)
Grober Plan ist bis ca. 10.11 einen groben Prototypen fertig zu haben.
Sonstige Neuerungen:
- Ein AtticProvider wurde implementiert. (Caching von input values)
- Eine Songklasse wurde implementiert (ein readonly Mapping) Diese sollen dann später auch die Distanzen zu allen anderen Songs kennen.
28. Oktober 2013¶
Gestern noch einen bugreport bei Readthedocs gefiled, die pushen auch gleich auf den produktionserver ohne vorher zu testen. überall Helden :) Hoffentlich geht der buidl bald wieder.
Heute das erste mal in der Doku das Wort “injektiv” (oder auch umkehrbar gnnant) benutzt. Fühl mich wie in Mathematikerelch. Bin mit dem Fahrrad in die FH gefahren, Zwille hat in Mathe wieder Matrizen bei Koeffizienten gesehen... Also ganz normal der Tag bisher.
30. Oktober 2013¶
Heute lange Diskussion mit Katzen über beide Projekte (morgen nochmal detailliert über seins). Neue Erkenntnis:
- Regeln gelten pro Key in der Attributmaske
- Eine Distanzmatrix ist schlicht zu teuer.
- Graph wird direkt aus Songliste gebaut.
- Jeder Song speichert N ähnlichste Songs. (N wählbar, sessionweit)
Sonstiger Grundtenor: Die Lösung ist schenjal. Im Babsi-Sinne, also negativ :)
Damit ich jetzt nochmal das Theme dastehen habe:
Implementierung und Evaluierung eines Musikempfehlungssytems basierend auf Datamining Algorithmen
4. November 2013¶
Einiges ist nun etwas gefestigt. Session caching ist implementiert.
Eine interessanter Vergleich von Graph-Performance:
Stimmt wohl gar nicht dass NetworkX meist fast gleich schnell ist. Hätte mich auch gewundert. Der Benchmarkgraph hat dann sogar vermutlich die gleich Dimensionen wie bei mir. 15 Stunden für “betweenness” ist daher kaum vertretbar.
Nächste Schritte:
- Graph builden (auf library einigen)
- Sich auf Datamining Framework einigen. (TextBlob? aber kein stemmer)
- __main__.py schreiben.
- moosecat auspacken, an mpd 0.18 anpassen und daten mal in libmunin reinschauffeln.
5. November 2013¶
Liebes Logbuch,
heute hab ich das Problem Dieter getroffen. Dieter ist recht träge und langsam... Ich muss alle 32k songs miteineander vergleichen. Nach einer ersten Hochrechnung dauert das in einem günstig geschätzten Fall doch seine 13 Stunden.. was etwas viel ist.
Eigentlich sollte das ja innerhalb von 5 Minuten geschehen sein (praktisch wie ein mpd datenbank update - zmd. erwartet das der user (der depp.))
Mögliche Ideen:
- Rating pro Song einführen (basierend auf Attribut Güte), for loop vergleicht nur songs bei denen die heuristic True liefert. Nachteil: Alles hängt von Güte der Heuristik ab. Vorteil: Ein ganzer Graph wird generiert. Die Heuristik könnte lernfähig sein.
- Aufteilung der Songs in Grüppchen, nur Vergleich innerhalb. Nachteil: Kein allgemeiner Graph, viele Untergraphen, Problem der verbinung dieser. Und was wäre überhaupt das Splitkriterium für die Gruppen?
Nachtrag:
6. November 2013¶
Liebes Logbuch,
Heute ging der Tag allein für Heuristiken drauf. Auf folgendes Vorgehen wurde sich nun geeinigt (ich mit mit meinem zweiten ich und christoph):
Wähle eine Gruppe von Attributen:
Dies erfolgt automatisch (beste N attribute die in 90% aller Songs vorkommen):
counter = Counter() for song in self._song_list: counter.update(song.keys()) print(counter.most_common())Alternativ kann der user diese selbst setzen.
Berechne die confidence von 1% der möglichen kombinationen. Stelle maximale Streuung (http://de.wikipedia.org/wiki/Korrigierte_Stichprobenvarianz) und average fest.
Iterationstrategie:
>>> song_list[::step=int(len(song_list) / 100)] # für große song_list >>> song_list[::step=int(len(song_list) / 10)] # len(song_list) < 1000 >>> song_list # len(song_list) < 100Wähle ein MAX_CONFIDENCE die diese Werte wiederspiegelt. (TODO: Gauss?)
Die Heuristik wird dann diese MAX_CONFIDENCE als Maß für die Vergleichbarkeit zweier Songs nehmen.
Edit vom 15. Dezember 2013: Hab den Eintrag heute gelesen. Musste laut lachen.
7. November 2013¶
Heuristik wurde verworfen.
Neuer Ansatz inspiriert von zuviel Kaffee, Seb und bestätigt durch dieses Paper:
- http://machinelearning.wustl.edu/mlpapers/paper_files/jmlr10_chen09b.pdf
- http://wwwconference.org/proceedings/www2011/proceedings/p577.pdf
Demnach hätte man folgende Schritte als Algorithmus:
- Basis-Distanzen: Sliding window über Songlist, evtl. auch andere Methoden.
- Refinement-Step: Schaue die indirekten Nachbarn jedes Songs an und vergleiche.
- DistanceToGraph: Aus einzelnen Distanzen Graph bilden.
Schritt 2) benötigt die Standardabweichung und Average von 1) um nur relevante Songs zu vergleichen.
Pseudo-code für refinement step:
def refine(song, max_depth=5, coming_from=None):
if max_depth is 0:
return
dfn = Song.distance_compute
add = Song.distance_add
# Thresholds sollten durch SD und mean abgeleitet werden.
for ind_ngb in song.indirect_neighbors(0.1, 0.2):
# Note: This does not prevent loops.
# It just makes them occur less likely.
if ind_ngb is coming_from:
continue
distance = dfn(song, ind_ngb)
add(song, distance)
if distance.distance < CONTINUE_DIFF:
refine(ind_ngb, max_depth=max_depth - 1)
18. November 2013¶
Obiger Ansatz hat prinzipiell gut geklappt.
Allerdings einige Zeit mit opimieren der distance_add Funktion verbracht. Diese wird sehr oft aufgerufen (genauso oft wie distance_compute), sollte daher möglichst schnell laufen. (bis zu 30% werden in dieser Funktion zugebrachgt momentan). Die erste primitive Version hatte noch eine lineare Komplexität. Nach einigen Versuchen konnte die Komplexität auf O(2 * log n). Dies ist zwar in den meisten Fällen nicht übermäßig schneller als der einfache aber lineare Algorithmus, skaliert aber deutlich besser wenn man die Anzahl der Nachbarn pro Song erhöht.
Man sollte hier vlt. mal ne Tabelle mit Messwerten anzeigen.
Der Ablauf beider Varianten ist derselbe, hier in Pseudo-Python dargestellt:
def distance_add(self, other, distance):
# Erlaube keine Selbstreferenzen:
if self is other:
return False
if self.bereits_bekannt(other):
if self.distance_get(other) < distance:
return False:
else:
self.update_with(other)
return True
if self.is_full():
worst_song, worst_distance = self.finde_schlechtesten()
if worst_distance < distance:
return False
# Achtung: Nur in eine Richtung!
# worst kennt immer noch self.
self.delete_oneway_link(worst)
self.update_with(other)
return True
def distance_finalize(self):
for neighbor, dist in self.distance_iter():
# Prüfe ob "Einbahnstrasse"
if neighbor.distance_get(self) is None:
neighbor.delete_oneway_link(self)
27. November 2013¶
Ein etwas längerer Eintrag heute hoffentlich.
Wirre Gedanken in keiner direkten Reihenfolge:
Eine interessante Datenbank wurde von Facebook released, die unter Umständen nützlich sein könnte: http://rocksdb.org/ (ein embedded KeyValue Store).
Momentanes Arbeitsgebiet #1: Traversierung des Graphen.
Momentanes Arbeitsgebiet #2: Implementierung der Listen History (Grouping/Rules).
Allgemein ist eine Re-Evaluierung von Regeln sinnvoll:
Ist es möglich dass es solche Regeln gibt wie artist:X --> genre:y = 1.0? Sprich dass Regeln auch von einem attrbut zum anderen gehen können.
Was ist mit Regeln die ineinander im Konflikt stehen?
``artist:X --> artist:Y = 0.0`` ``artist:Y <-> artist:X = 0.5``
Wann sollten Regeln gelöscht werden? Ist die Herangehensweise eines Timestamps wirklich sinnvoll?
Wie sollen allgemein Regeln gefunden werden? Apriori oder FP-Growth? Basierend auf welchen Warenkörben?
- Momentanes Arbeitsgebiet #3: Moosecat in akzeptablen Zustand bringen. Vlt. momentan eine simpleren Client entwickeln basierend auf libmoosecat?
- Momentanes Arbeitsgebiet #4: Weiter Testen und Dokumentation nach vorne bringen. TravisCI bildet momentan auch grade nicht aus nicht definierten Gründen. Besonders das Testen des Graphen könnte schwierig werden.
- Momentanes Arbeitsgebiet #5: Hinzufügen und Löschen von einzelnen Songs. Diese können den Graphen unter Umständen “unsauber” machen, deshalb wäre eine Gedanke nach einigen remove/insert Operationen einen rebuild anzustoßen. Apropos rebuild: Eine AsyncSession wäre fur die Moosecat Integration recht wichtig.
Randnotizen:
- Große Graphen mit neuer Visualisierung: http://i.imgur.com/9Sxob0W.jpg
- Das Database Objekt sollte auch die Anzahl der Listens abspeichern.
- Für das Hinzufügen/Löschen einzelner Songs sowie für Breadth First Search sind Visualisierungen beim Erklären sehr hilfreich.
28. November 2013¶
Randnotizen:
- Hab heute den mit Abstand schreckclichsten Python Code gelesen: http://www.borgelt.net/python/pyfim.py
3. Dezember 2013¶
Heutige Aufgabe:
Die 3000 Integer Werte starke Moodbar (die nach eingängier Meinung eigentlich freqbar heißen sollte) möglichst akkurat in wenigen Werten zu beschreiben und vergleichbar zu machen.
Werte die aus einer einzelnen moodbar extrahiert werden:
Pro Farbkanal:
Beschnittenes Histogramm mit 5 höchsten Werten (von 15)
Indikator für die dominierenden Frequenzen innerhalb dieses Bands. (sehr grobe Abschätzung der Instrumente).
Diffsum: Die Summe der Differenzen von letzten Wert zum nächsten. (0 - samples * 255)
Indikator für die Abwechslungsreichheit der Daten.
Dominante Farben: Die 10 häufigsten, gerundeten, nicht-schwarzen, Farbtripel.
Alle Farbkanäle werden auf 17 mögliche Werte abgebildet und dann gezählt. Sehr dunkle Farbtripel werden nicht gezählt. E-Gitarren sind beispielsweise türkis, bestimmte Farben, bzw. Farbbereiche repräsentieren daher recht fein verschiedene Instrumente.
Blackness.
Der Schwarzanteil (bzw. Anteil sehr dunkler Farben) repräsentiert den Anteil der stillen Abschnitte im Lied.
Durschschnittliches Maximum und Minimum.
Weiche Ober- und Untergrenze der Werte in denen sich die RGB Werte für gewöhnlich bewegen.
Speicherverbrauch:
(10 * 4 + 2 + 3 * 4 + 1) * 8 = 536 Bytes
Zwar gnädig gerechnet, aber braucht die ganze moodbar ja immerhin:
3000 * 8 = 24.000 Bytes
Wir profitieren davon dass sich alle Werte im Bereich von 0 bis 255 befinden, so dass diese nicht allokiert werden müssen und allein durch Referenzen (8 Byte) repräsentiert werden.
Vergleich der einzelnen Beschreibungen:
| Name | Weight | Formula |
|---|---|---|
| diffsum | 0.135 | min(((v1 + v2) / 2) / 50, 1.0) |
| histogram | 0.135 | sum(diff(common_v1, common_v2) / 255) / (5 - len(common)) |
| dominant colors | 0.63 | number of common(weight=1)/similar(weight=0.5) colors / 5 |
| blackness | 0.05 | abs(v1 - v2) / max(v1 - v2) |
| average min/max | 0.05 | abs(v1 - v2) / max(v1 - v2) |
| 1.0 |
Beispielausführung:
Randnotizen:
Playlist Ersteller mit wunderbaren Namen (gay-jay):
Sogar die sächsische Polizei kennt Shazam, hoffentlich kontaktieren die mich nicht...:
5. Dezember 2013¶
Allgemeine Moodbar Problematiken die ich hier festhalte:
Unterschiedliche Stückqualität und v.a. Unterschiede in Dynamic Range.
Siehe dazu: http://pleasurizemusic.com/de
Lieder die (u.a. fälschlich) längere Stille haben nach dem Lied (auch bei Hidden Tracks zB.) werden nicht allzu gut behandelt.
Verrauschte Live-Versionen werden oft mit stark E-Gitarren haltiger Musik gruppiert. (zB. mit Before the Hangman’s Noose -> Abschiedslied)
Generell lassen sich Lieder mit verzerrten E-Gitarren und starken Einsatz von Drums relativ schlecht matchen.
Die Leiche :-)
Anonsten funktionier die Moodbar Analyse einigermaßen gut (*):
[Y] 0.22408: 11 Der Letzte Stern (reprise).mp3 -> 03 Lieder übers Vögeln.mp3
[N] 0.22500: 08 Das letzte Einhorn & Vince - Spielmann.mp3 -> 1-08 Die Leiche.mp3
[N] 0.22870: 13 In Extremo - Rasend Herz.mp3 -> 17 OK _ Kein Zurück.mp3
[N] 0.22986: 03 Lieder übers Vögeln.mp3 -> 19 Immer noch.mp3
[Y] 0.23770: 16 Der ziemlich okaye Popsong.mp3 -> 13 Lieber Staat.mp3
[N] 0.24097: 07 Auferstehung.mp3 -> 05 Der Tod und das Mädchen.flac
[Y] 0.24808: 22 Abschiedslied.mp3 -> 18 Unter Wasser.mp3
[Y] 0.25127: 08 In Extremo - Omnia Sol temperat.mp3 -> 13 In Extremo - Rasend Herz.mp3
[Y] 0.25470: 05 Glücklich.mp3 -> 13 Lieber Staat.mp3
[Y] 0.26314: 03 Am Strand.mp3 -> 17 OK _ Kein Zurück.mp3
[N] 0.26566: 12 The Fury of Our Maker's Hand.mp3 -> 22 Abschiedslied.mp3
[N] 0.26720: 11 Der Letzte Stern (reprise).mp3 -> 19 Immer noch.mp3
[N] 0.27299: 13 In Extremo - Rasend Herz.mp3 -> 02 Augenblick.mp3
[N] 0.27458: 10 Lebenslehre.flac -> 1-08 Die Leiche.mp3
[N] 0.27858: 09 In Extremo - Küss mich.mp3 -> 13 Kind im Brunnen.mp3
[Y] 0.27868: 08 In Extremo - Omnia Sol temperat.mp3 -> 03 In Extremo - Vollmond.mp3
[N] 0.28066: 1-08 Die Leiche.mp3 -> 10 Phänomenal egal.mp3
[N] 0.28091: 05 Sin & Sacrifice.mp3 -> 04 Ohne Herz.mp3
[N] 0.28459: 04 Hold Back the Day.mp3 -> 08 Mayday Mayday.mp3
[N] 0.28478: 12 The Fury of Our Maker's Hand.mp3 -> 17 OK _ Kein Zurück.mp3
[N] 0.28585: 06 Silbermond - Die Gier.mp3 -> 1-05 Krieg.mp3
[Y] 0.28654: 03 In Extremo - Vollmond.mp3 -> 01 Blind - Ave Maria.mp3
(*)
Manchmal werden Lieder gefunden die tatsächlich eine ähnliche moodbar haben sonst aber ziemlich unterschiedlich sind.
Randnotizen:
- Empfehlung des Tages: Wer hat uns verraten => Die Leiche
7 Dezember 2013¶
Mögliche Ideen:
Beats per Minute Detection
λ file='wir_reiten.mp3' λ sox -v 0.5 $file -t raw -r 44100 -e float -c 1 - | ./bpm 128.008Noch weitaus kompliziertere Analysen sind mithilfe der aubio Bibliothek machbar:
Beispielsweise:
- several onset detection methods
- different pitch detection methods
- tempo tracking and beat detection
Empfehlungen die neben den entsprechenden Song auch eine Begründung liefern. Beispiel:
- Requested 5 recommendations for Song #123. - Affected Rules are: [123, 345] -> [111] [123] -> [222, 333] Using [111, 222, 333] as additional bases. - Neigbors of 123: [456, 789, 222] - Neigbors of 111: [333, 777] - Neigbors of 222: [444, 555] - Neigbors of 333: [999] - Yielding: * Recomending 456, because of: - similar moodbar (0.1) - similar genre (X <-> Y) ...
Vergleich zu Mirage einbringen:
Hauptsächlich:
Mirage nutzt nur Audiodaten, und anaylisiert diese anhand eines ausgeklügelten statistischen Datenmodells. Mirage scheint zudem weniger auf große Datenmengen ausgelegt zu sein, alle
libmunin nutzt auch andere Daten wie lyrics, tags etc. und vergleicht diese anhand generischer Datamining Strategien. Die Funktionalität von Mirage könnte daher durch verschiedene Provider und Distanzfunktionen integriert werden. Zudem funktioniert Mirage nur mit einem Player (Banshee) während libmunin prinzipiell mit allem arbeiten kann dass irgendwie die nötigen Informationen beschaffen kann.
10 Dezember 2013¶
Randnotizen:
Da eine normalisierte Datenbank oft hilfreich ist mit libmunin:
Es gibt mehr als einen aktiv entwickelten MPD Server:
Manchmal entstehen hübsche blümchen:
Eine Art Konkurrent ist auch noch MusicSquare, finde leider keinen Link dazu. Angeblich solls aber recht bekannt sein und die Demo war recht nett.
Interessante Seite vlt. noch:
19 Dezember 2013¶
Hach, ja. Tägliches Schreiben ist schwer...
In der Zwischenzeit ist viel und doch nicht viel passiert. libmunin hat die ersten echten Empfehlungen gegeben, es gibt einen neuen Beats-per-Minute-Provider und generell haben sich viele bugs verabschiedet.
Heute war die Implementierung des RAKE Algorithmus dran. Kurz für (Rapid Automatic Keyword Extraction). Dieser kann aus beliebigen texten die wichtigsten Keywords extrahieren.
Beispiellauf:
λ ~/dev/libmunin/ master* glyrc lyrics -a "the beatles" -t 'yellow submarine'
1. Artist : the beatles
2. Title : yellow submarine
3. Language : de
4. Type : lyrics
---- Triggering: musictree
---- Triggering: local
---- Triggering: lyricswiki
----
///// ITEM #1 /////
WRITE to './the beatles__yellow submarine_lyrics_1.txt'
FROM: <http://lyrics.wikia.com/The_Beatles:Yellow_Submarine>
PROV: lyricswiki
SIZE: 1270 Bytes
MSUM: 7d229df74bd4e39193773180c25224f0
TYPE: songtext
SAFE: No
RATE: 0
STMP: 0,000000
DATA:
In the town where I was born
Lived a man who sailed to sea
And he told us of his life
In the land of submarines
So we sailed on to the sun
Till we found a sea of green
And we lived beneath the waves
In our yellow submarine
We all live in a yellow submarine
Yellow submarine, yellow submarine
We all live in a yellow submarine
Yellow submarine, yellow submarine
And our friends are all aboard
Many more of them live next door
And the band begins to play
We all live in a yellow submarine
Yellow submarine, yellow submarine
We all live in a yellow submarine
Yellow submarine, yellow submarine
Spoken:
Full steam ahead, Mr. Boatswain, full steam ahead
Full steam ahead it is, Sergeant
Cut the cable! Drop the cable!
Aye-aye, sir, aye-aye
Captain, captain
As we live a life of ease
Every one of us (every one of us) has all we need (has all we need)
Sky of blue (sky of blue) and sea of green (sea of green)
In our yellow (in our yellow) submarine (submarine, ha-ha!)
We all live in a yellow submarine
A yellow submarine, yellow submarine
We all live in a yellow submarine
A yellow submarine, yellow submarine
We all live in a yellow submarine
Yellow submarine, yellow submarine
We all live in a yellow submarine
Yellow submarine, yellow submarine
//////////////////////////////////
λ ~/dev/libmunin/ master* cat the\ beatles__yellow\ submarine_lyrics_1.txt | python munin/rake.py
36.000: frozenset({'full', 'steam', 'ahead'})
8.000: frozenset({'eas', 'everi', 'one'})
7.333: frozenset({'live', 'door', 'next'})
4.000: frozenset({'sun', 'till'})
4.000: frozenset({'told', 'us'})
4.000: frozenset({'mani', 'aboard'})
4.000: frozenset({'band', 'begin'})
4.000: frozenset({'cut', 'sergeant'})
3.900: frozenset({'submarin', 'yellow'})
3.333: frozenset({'born', 'live'})
3.333: frozenset({'beneath', 'live'})
1.000: frozenset({'wave'})
1.000: frozenset({'captain'})
1.000: frozenset({'life'})
1.000: frozenset({'drop'})
1.000: frozenset({'friend'})
1.000: frozenset({'sky'})
1.000: frozenset({'found'})
1.000: frozenset({'sea'})
1.000: frozenset({'town'})
1.000: frozenset({'land'})
1.000: frozenset({'play'})
1.000: frozenset({'man'})
1.000: frozenset({'green'})
1.000: frozenset({'sail'})
Beschreibung des Algorithmus (damit ichs net wieder vergess):
Aufteilung des Textes in Sätze (anhand von Interpunktion).
Extrahierung der Phrases (Sequenzen von Nichtstoppwörtern) aus den Sätzen.
Berechnung der Wordscores für jedes Wort in einem Phrase:
\(score(word) = \frac{degree(word)}{freq(word)}\)
wobei:
\(degree(word) = len(phrase) - 1\)
\(freq(word) = \sum count(word) \forall word \in corpus\)
Zusammsetzen der Keywords, der Score eines Keywords ist definiert als:
\(\sum score(word) \forall word \in phrase\)
Das war der ursprüngliche Algorithmus, als Erweiterung von mir dazu:
- Die Sprache wird mithilfe des guess_language modules geschätzt und eine entsprechende Stoppwortliste wird geladen.
- Wörter werden gestemmt, mithilfe des Snowball-Stemmers, der ebenfalls die Sprache berücksichtigt.
- Keywords werden als sets zusammengefasst, dies erleichtern Teilmengenuntersuchungen.
- Sets die eine Untermenge anderer Keywordsets bilden werden entfernt, da diese keine weiter Informationen beinhalten. Beispiels weise wurden die sets {‘yellow’} und {‘submarine’} entfernt da beide eine Untermenge von {‘yellow’, ‘submarine’} waren.
Die ursprüngliche Idee stammt aus diesem Buch (Textmining: Applications and Theory):
Nächste Ziele:
- Sieve Klasse bauen die Recommendation, die aus Usersicht, unter Umständen falsch sein könnten rausfiltert.
- LyricsProvider schreiben.
- Demoanwendung mit libmoosecat.so.
- Möglichkeit um generelle Daten session übergreifen zu speichern.
26 Dezember 2013¶
Randideen:
- Implementierung eines DBUS-Service/Clients fur remote sessions.
- Erwähnung von zeitgeist + integration von libmunin darin.
7 Januar 2013¶
Ein Ende der Implementierung ist in Sicht.
Kein DBUS Daemon, nur skizzenhaft als Source - nur möglichkeit erwähnen.
- Idee: Nicht nur die gehörten Songs ins Lernen einbeziehen, sondern auch die
nicht gehörten. Sollte die Anzahl der gehörten songs groß genug sein und die playlist größe ausreichend klein im vergleich dazu, kann man vermuten dass nie gelistende songs eher unwichtig sind. vlt. auch datum mit einbeziehen? (Spinnerei :)
Sonst: GUI Implementiert.
14 Januar 2013¶
Täterätäääää! Dschingderassa Bumm Bumm Bumm!
Angepeilt war bis zum 15ten Januar fertig zu werden mit der Implementierung, und wie das Schicksal so ist kommt es scheinbar genau so. Die GUI ist soweit fertig, und das einzige was noch zu machen bleibt sind ein paar Songs zur Testdatenbank zu adden, so dass man ca. 2000 Songs hat - was denk ich für die ersten Testruns eine repräsentative Menge ist.
Ein Bild von der GUI:¶
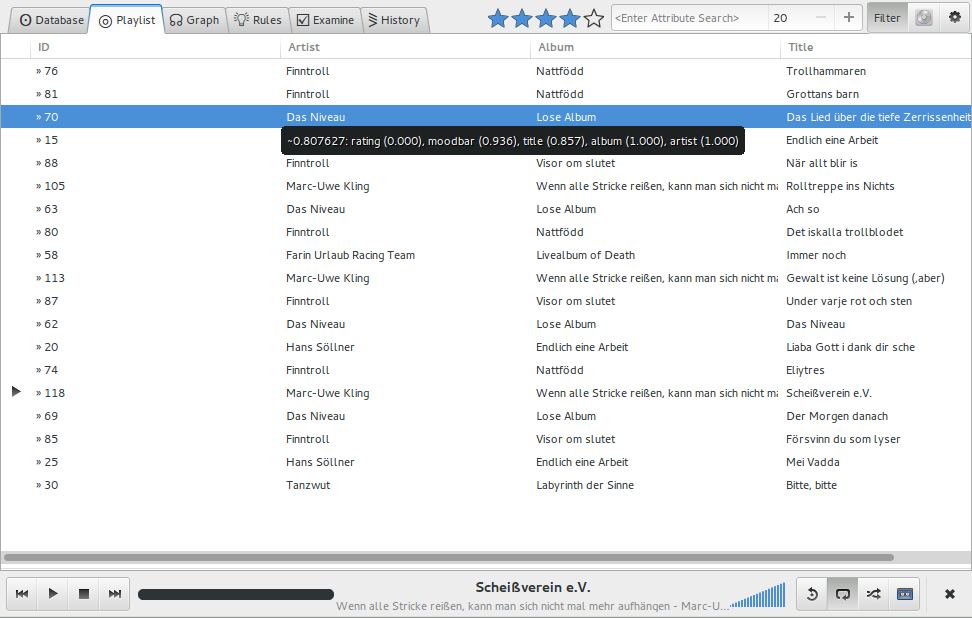
Das nächste wird dann sein sich mitteils sphinxtr ein Template für Projekt- und Bachelorarbeit zu erstellen: https://github.com/jterrace/sphinxtr
Neulich bei heise:
http://research.google.com/bigpicture/music/
Mögliche Zukunftsspinnerei:
- Einbau von munin in mopidy (weil immer ein client listenen muss sonst)
- Einstellungsmöglichkeit der Session in gui
- Statistiken in Einleitung (~5000 LoC Python etc.)
Moosecat:
- Query Syntax: Quotation marks und Ranges. Einfach weil mans kann :)
Table Of Contents
- Logbuch: developement log (german)
- 14. Oktober 2013
- 15. Oktober 2013
- 16. Oktober 2013
- 17. Oktober 2013
- 23. Oktober 2013
- 28. Oktober 2013
- 30. Oktober 2013
- 4. November 2013
- 5. November 2013
- 6. November 2013
- 7. November 2013
- 18. November 2013
- 27. November 2013
- 28. November 2013
- 3. Dezember 2013
- 5. Dezember 2013
- 7 Dezember 2013
- 9 Dezember 2013
- 10 Dezember 2013
- 19 Dezember 2013
- 26 Dezember 2013
- 7 Januar 2013
- 14 Januar 2013
Related Topics
- Documentation overview
- Previous: Documents
This Page
Useful links:
Package:

{kind=link}
{kind=link}
{kind=link}
Github: